babel 的原理及插件的编写(简要)
由浅入深,先从几个简单的插件的编写开始吧
(本次分析的 babel 版本为 7.20.4)
实现一个自动将 console.log 信息加上所属代码的位置(行列)信息的 babel 插件
例子代码:
1 | function test() { |
- 首先查看这段代码对应的 AST 结构
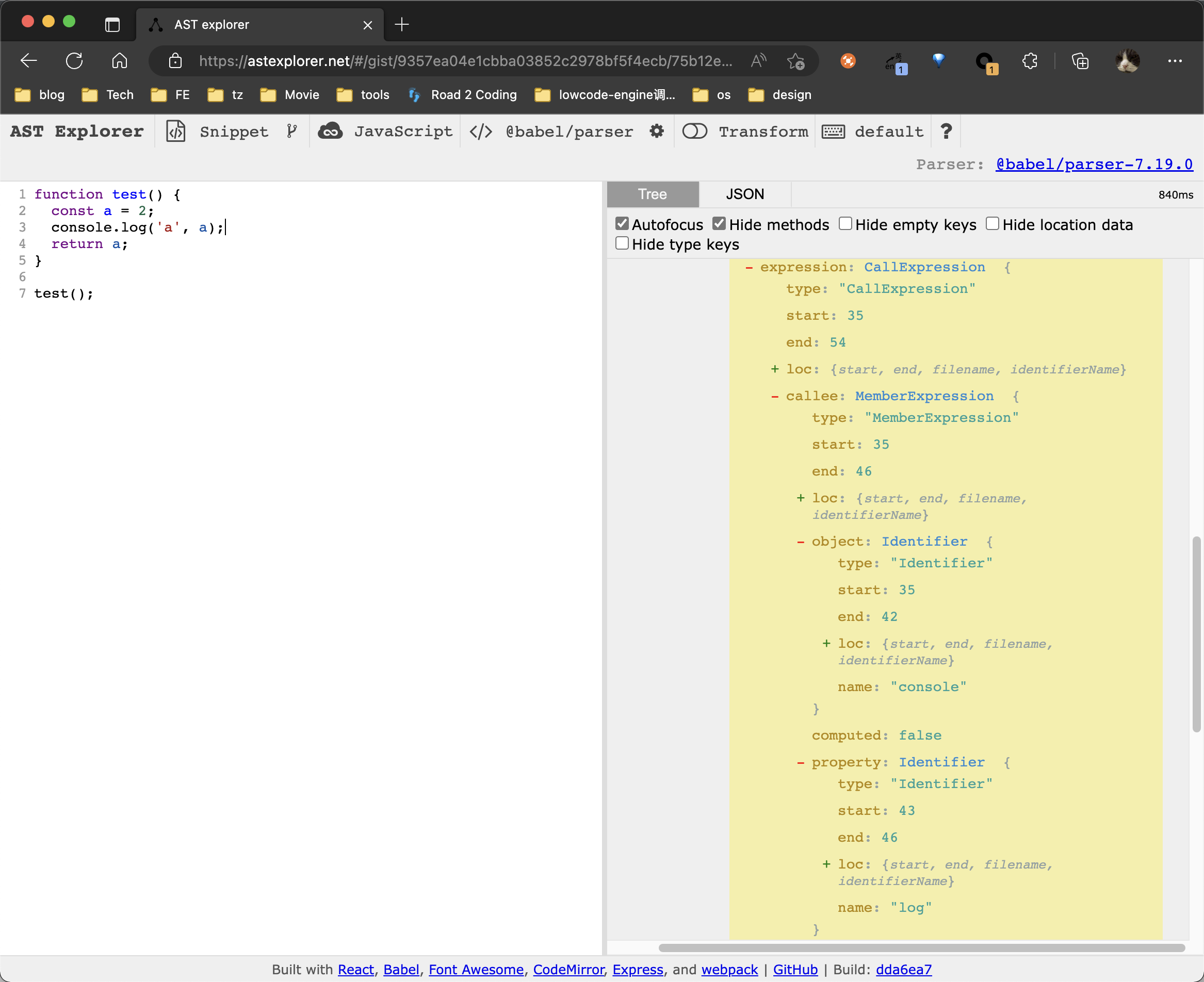
在上图可以看到
console.log对应的节点类型为CallExpression -> MemberExpress -> Identifier,所以我们的思路是:- 找到类型为 CallExpression 的节点
- 判断其代码是否是 console.log
- 拿到位置信息
- 插入到 arguments 数组中
具体实现代码:
1 | const babel = require("@babel/core"); |
执行结果:
把代码里的 标识符n 转换为 标识符x
1 | // 下面的逻辑是把 代码里的 标识符n 转换为 标识符x |
上面实现了一些简单的 babel 转换插件,实现思路也很清晰了,整体的思路就是:
1 | code -> AST -> transformed AST -> transformed code |
下面分析下其基本原理。
首先简单介绍下什么是 AST
AST(abstract syntax tree),即抽象语法树。
关键的概念
- Tokenizer 分词: 将整个代码字符串分割成语法单元数组(token)
JS 代码中的语法单元主要指如标识符(if/else、return、function)、运算符、括号、数字、字符串、空格等等能被解析的最小单。 可以看下这个在线分词工具;
2.语法分析: 在分词结果的基础上分析语法单元之间的关系。
语义分析则是将得到的词汇进行一个立体的组合,确定词语之间的关系。
先理解两个重要概念,即语句和表达式。
1 | var a = 1 + 2; |
语句(statement),👆上面就是一条语句,一般情况下,在js里每一行就是一个语句。
表达式(expression),如上面的 1 + 2就是表达式,是指最终有返回结果的一小段代码,可以嵌入到另一个表达式,且包含在语句中。
简单来说语法分析是对语句和表达式识别,这是个递归过程,在解析中,babel 会在解析每个语句和表达式的过程中设置一个暂存器,用来暂存当前读取到的语法单元,如果解析失败,就会返回之前的暂存点,再按照另一种方式进行解析,如果解析成功,则将暂存点销毁,不断重复以上操作,直到最后生成对应的语法树。
先看下编译原理中,词法分析到语法分析阶段图: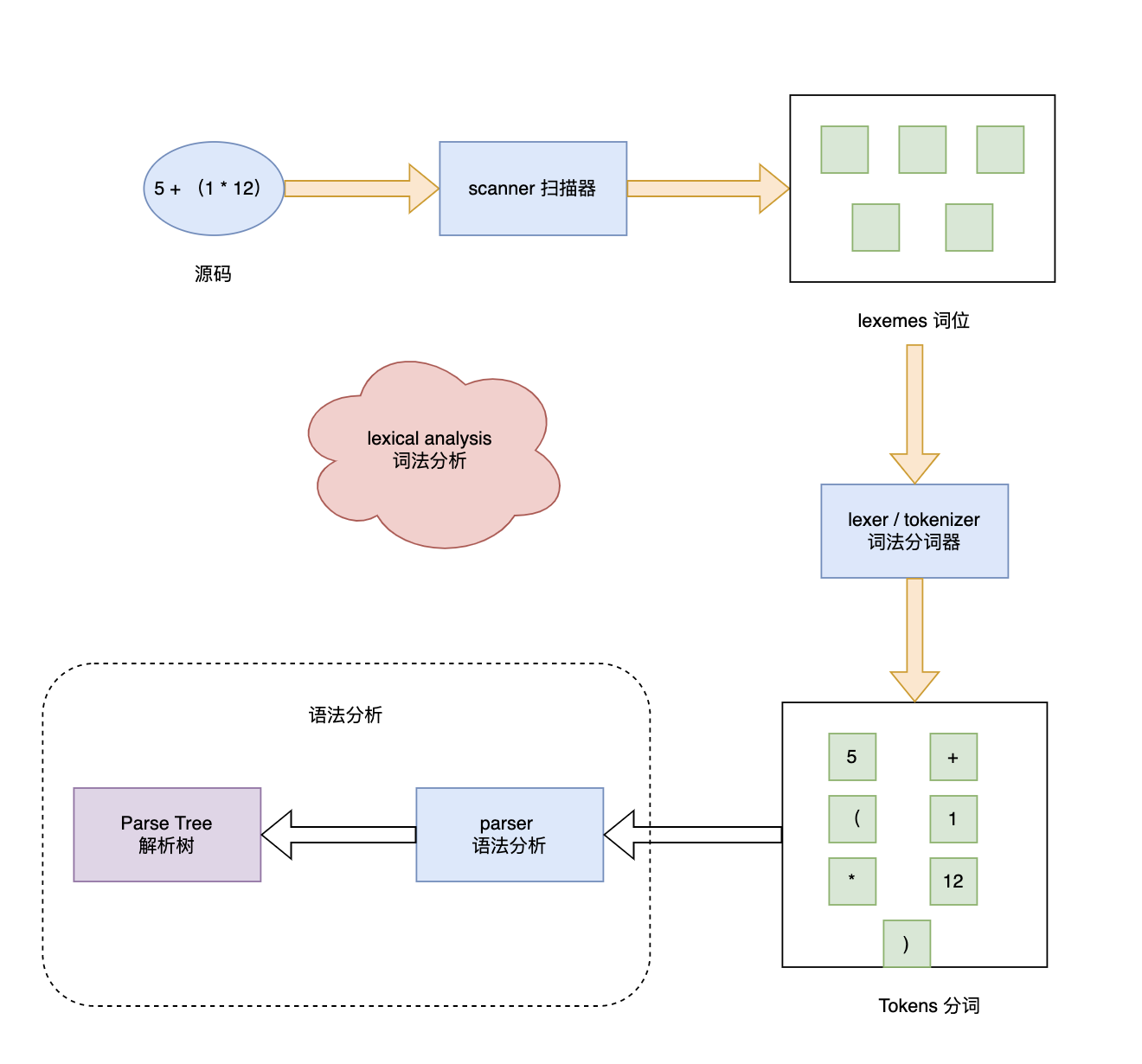
上面的产物 parse tree 即解析树,代表了源码的所有信息,很详细,也很冗余(包含分号,冒号等),而 AST,抽象了一些,即精简了 parse tree:
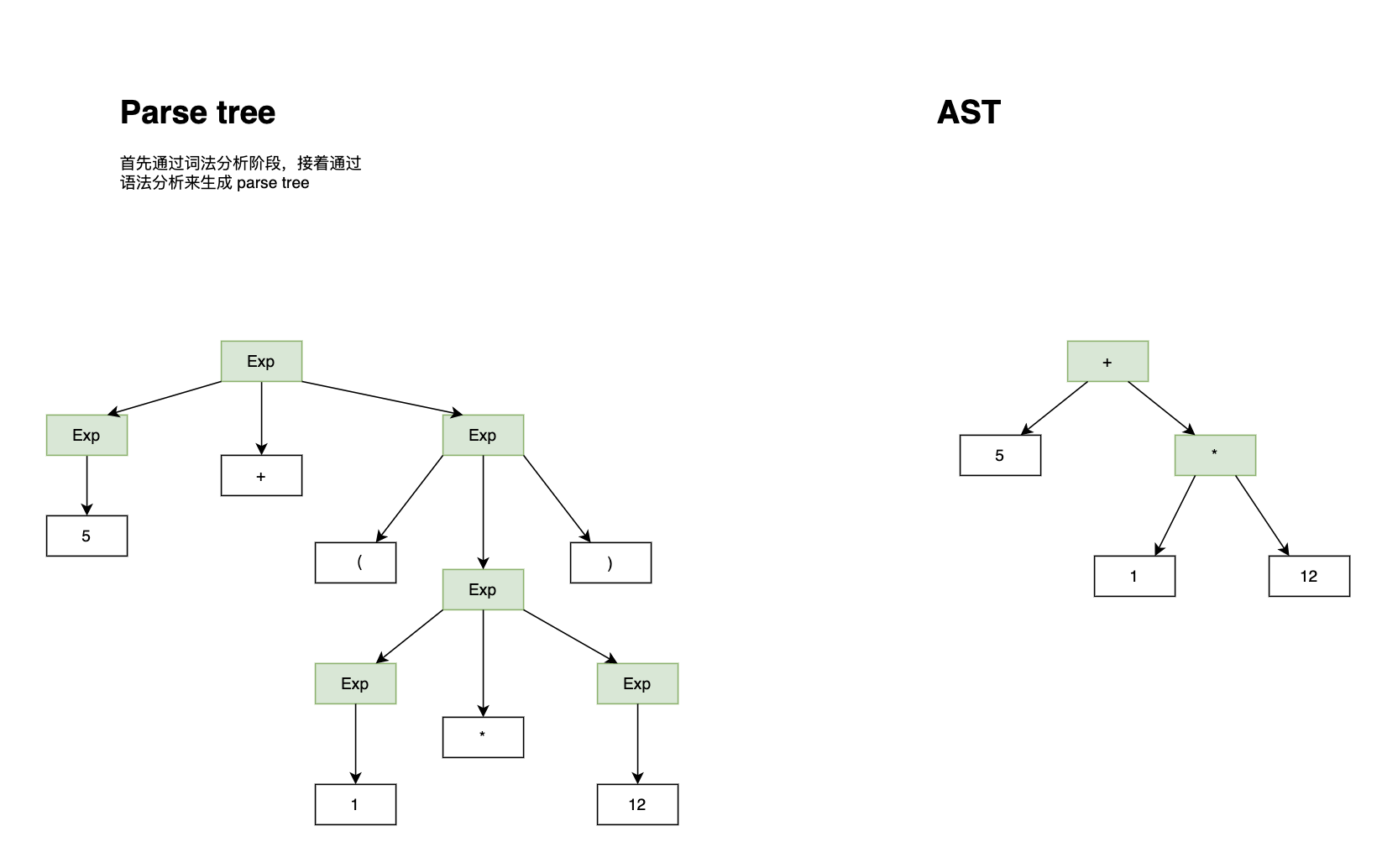
- AST不含有语法细节,比如冒号、括号、分号
- AST会压缩单继承节点
- 操作符会变成内部节点,不再会以叶子节点出现在树的末端。
那 babel 怎么将代码转为 AST 的?
根据文档可知要在 packages/babel-parser 里找逻辑
1 | # 在 babel 源码目录里执行 |
1 | // test-parser.js |
1 | # 通过下面的命令执行 jest |
查看 parse 函数源码,得到其执行路径: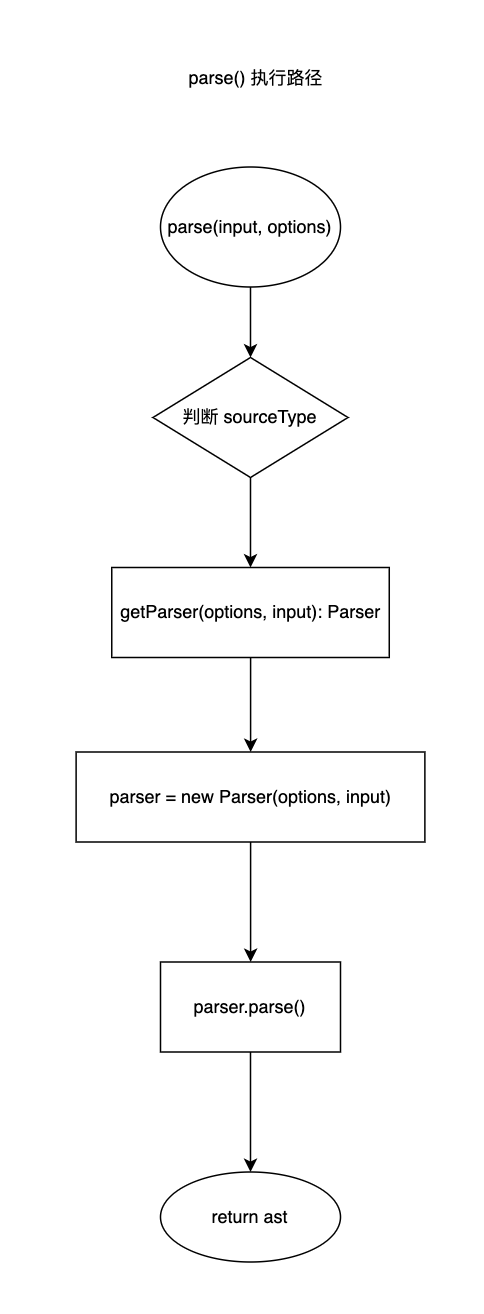
其中 Parser 类继承关系: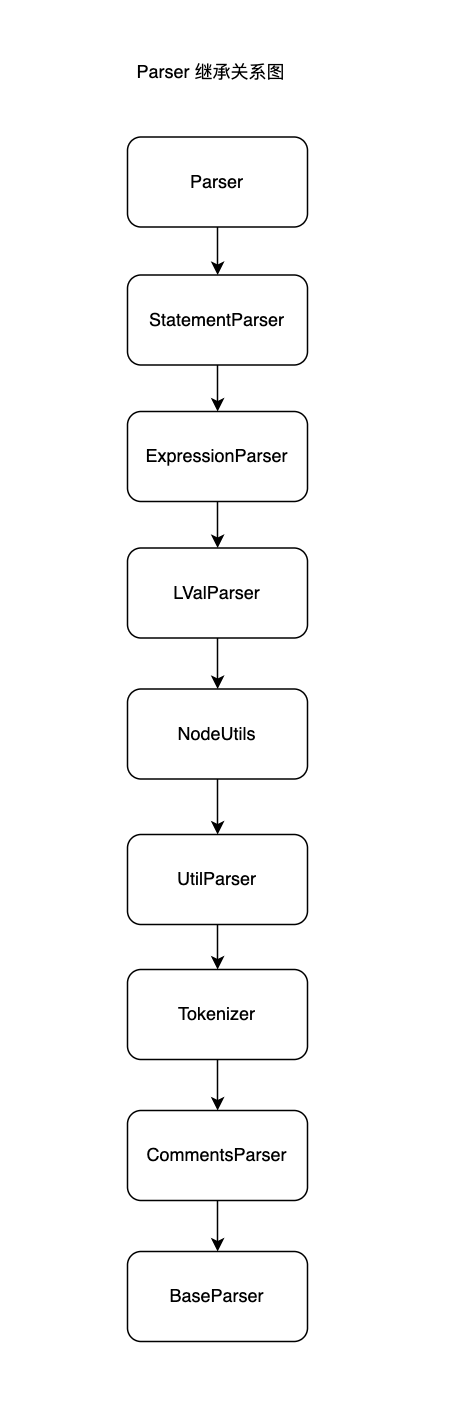
关注点转移到 parser.parse() 函数中,查看源码::
1 | parse(): N.File { |
关注点转移到 this.nextToken() 方法
1 | // 获取并更新下一个 token 信息 |
感兴趣的可以继续查看
getTokenFromCode的实现逻辑,这里其实就是 tokenzier 的核心逻辑
关注点转移到 parseTopLevel() -> parseProgram -> parseBlockBody -> parseBlockOrModuleBlockBody -> parseStatement -> parseStatementContent
具体逻辑可以查看 github 上添加的代码注释。
babel 是如何遍历 ast的?
在 packages/babel-traverse 有两个关键的对象:
Visitor
对于这个遍历过程,babel 通过实例化 visitor 对象完成,其实我们生成出来的 AST 结构都拥有一个 accept 方法用来接收 visitor 访问者对象的访问,而访问者其中也定义了 visit 方法(即开发者定义的函数方法)使其能够对树状结构不同节点做出不同的处理,借此做到在对象结构的一次访问过程中,我们能够遍历整个对象结构。(访问者设计模式:提供一个作用于某对象结构中的各元素的操作表示,它使得可以在不改变各元素的类的前提下定义作用于这些元素的新操作)
遍历结点让我们可以定位并找到我们想要操作的结点,在遍历每一个节点时,存在enter和exit两个时态周期,一个是进入结点时,这个时候节点的子节点还没触达,遍历子节点完成的后,会离开该节点并触发exit方法。
Path
Visitors 在遍历到每个节点的时候,都会给我们传入 path 参数,包含了节点的信息以及节点和所在的位置,供我们对特定节点进行修改,之所以称之为 path 是其表示的是两个节点之间连接的对象,而非指当前的节点对象。path属性有几个重要的组成,主要如下: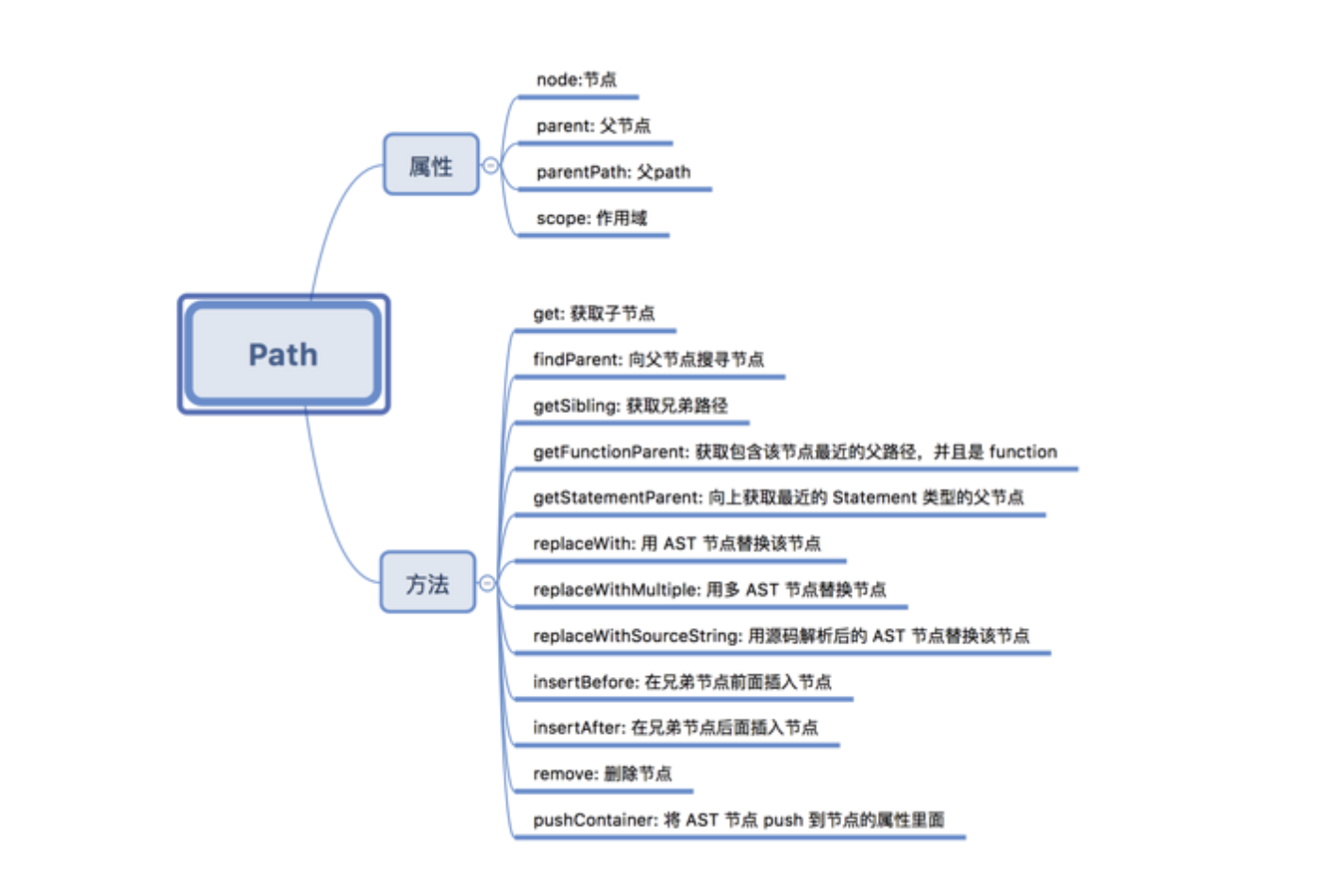
关键路径:
1 | // babel-traverse |
参考资料
Leveling Up One’s Parsing Game With ASTs
彩蛋:Babel song
Hallelujah —— In Praise of Babel